Demografische Cluster
Selbst wenn man sich vor Beginn der Befragung bereits Gedanken darüber gemacht hat, welche Charakteristika einzelne Teile der Zielgruppe haben, kann es vorkommen, dass innerhalb der Befragten Clustering vorliegt. Zeigt die diskrete Auswertung der Kano-Befragung zum Beispiel, dass einzelne Features nicht eindeutig einer der Kategorien zugeordnet werden können, ist dies ein Hinweis auf vorliegende Gruppierungen mit unterschiedlicher Meinung zum Feature.
Offensichtlich sind sich die Befragten nicht einig, welcher Kategorie sie Feature eins zuordnen. Ein Hinweis auf Cluster innerhalb der Zielgruppe: eine Gruppe sieht die Funktionalität als Basis-Feature an, eine zweite lehnt sie ab.
Ein weiterer Anhaltspunkt kann ein Gleichgewicht zwischen positiver und negativer oder gleichgültiger Bewertung sein. Dabei gelten als positive Bewertung die Kategorien Basis, Leistung und Begeisterung. Liegt wie bei Feature zwei ein Gleichgewicht vor, sollte darüber nachgedacht werden, die Zielgruppe erneut zu analysieren.

Meinungs-Gleichgewicht für Feature zwei (positiv: 4+5+3=12, negativ oder gleichgültig: 3+1+7=11)
Generell kann das weitere Segmentieren der Zielgruppe sinnvoll sein, wenn eine große Anzahl an Testpersonen befragt wurde. Zeigen sich keine auffälligen Antwortmuster, kann trotzdem das Gruppieren und Untersuchen von Personen, welche einer der zuvor erarbeiteten Personas besonders ähneln, aufschlussreich sein. Zeigt sich in Folge, dass sich die Meinung zu einzelnen Eigenschaften des Produkts zwischen verschiedenen Segmenten der Zielgruppe stark unterscheidet, sollte das Entwicklungsteam darüber nachdenken, solche Features nur für den entsprechenden Teil der Zielgruppe anzubieten.
Ausmaß des Einflusses auf die Kundenstimmung: Satisfaction Koeffizient
Ein statistischer Kennwert, welcher relativ direkt aus den vorhandenen Daten hervorgeht, ist der Satisfaction bzw. Dissatisfaction Koeffizient für die einzelnen Features. Die beiden Werte geben für jedes Feature an, wie stark das Feature die Stimmung der Nutzer beeinflusst. Die Berechnung ist auf Basis der vorhandenen Anzahlen – welche Ergebnis der diskreten Auswertung der Kano Analyse sind – recht simpel:

Beispiel für die Berechnung der Koeffizienten für Feature drei
Je stärker der Satisfaction Koeffizient von Null abweicht, desto stärker beeinflusst das Vorhandensein des Features die Stimmung der Kunden positiv – je stärker der Dissatisfaction Koeffizient von Null abweicht, desto stärker beeinflusst das nicht Vorhandensein des Features die Stimmung der Kunden negativ. Dabei sind die Koeffizienten einzeln schwer interpretierbar, machen die Features aber untereinander vergleichbar und liefern so einen weiteren Anhaltspunkt für ihre Priorisierung (vor allem in Trade-off Situationen).
Sofern eine kontinuierliche Auswertung der Kano-Analyse vorhanden ist (wie sie z.B. unser Kano+ Tool liefert) können Auswirkungen auf die Kundenzufriedenheit auch ohne weitere Berechnung anhand dieser abgelesen werden. Hier gilt: je weiter rechts ein Feature sich im Schaubild befindet, desto stärker negativ beeinflusst seine Abwesenheit die Stimmung der Nutzer. Umso weiter oben ein Feature im Schaubild platziert ist, umso stärker beeinflusst sein Vorhandensein die Stimmung der Nutzer positiv. Insgesamt beeinflussen also diejenigen Features, welche sich am weitesten in der oberen rechten Ecke befinden die Kundenzufriedenheit am stärksten positiv.
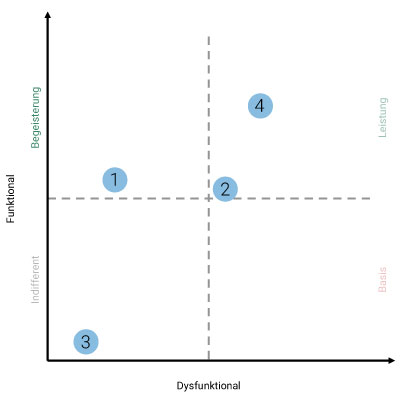
Auch aus der kontinuierlichen Auswertung kann die Wichtigkeit der Features abgelesen werden. Im Beispiel besonders wichtig: Features zwei und vier.
Manche Quellen zum Thema Kano bilden im Rahmen der kontinuierlichen Analyse auch die Standardabweichung der Bewertung ab. Da die Standardabweichung bei einer Kano-Analyse lediglich Informationen darüber enthält, wie einig die Befragten sich in ihrer Bewertung sind, stellt sich allerdings die Frage, ob dieser zusätzliche Aufwand sich lohnt.
Direkte Abfrage der Wichtigkeit von Funktionalitäten
Um abzuschätzen, wie wichtig einzelne Funktionalitäten eines Produktes dem Nutzer sind, könnte man natürlich auch direkt nachfragen. Nutzt man diese Methode, so muss man den klassischen Kano-Fragebogen etwas erweitern. Hierbei gibt man den Befragten die Möglichkeit, den Features zusätzlich zu den beiden vorgegebenen Fragen noch eine Wichtigkeit zuzuweisen. Denkbar ist hier beispielsweise eine einfache Skala von eins bis zehn, oder das Einsortieren aller Features auf einer Rangliste mit den Plätzen eins bis n, wobei n der Anzahl der untersuchten Features entspricht. Auf den ersten Blick erscheint diese Methode naheliegender als das Berechnen von Koeffizienten. Allerdings haben die Verfahren nicht zu unterschätzende Nachteile:- Das Einstufen der Features auf einer Rangliste fordert die Befragten mehr als die übliche Kano-Befragung. Um eine Rangliste erstellen zu können, müssen die Befragten alle untersuchten Features im Kopf haben und miteinander vergleichen.
- Lässt man die Feature-Wichtigkeit auf einer Skala von eins bis zehn bewerten, besteht die Gefahr, dass die Teilnehmer alle vorgeschlagenen Features als extrem wichtig einstufen.
Natürlich könnte man argumentieren, dass eine direkte Abfrage die bewusste Wichtigkeit erfasst, während die Satisfaction Koeffizienten die Wichtigkeit implizit erfassen. Man könnte also annehmen, dass unterschiedliche Konzepte erfasst werden. Studien in diesem Bereich zeigen allerdings, dass die Ergebnisse auf direkte Nachfrage stark mit den berechneten Koeffizienten korrelieren¹. Es ist also davon auszugehen, dass der Unterschied in der Aussage beider Kennwerte gering ist. Angesichts der Tatsache, dass sich die Satisfaction Koeffizienten ohne Weiteres aus den erhobenen Daten ergeben, ist eine direkte Abfrage der Wichtigkeit in den meisten Fällen unnötiger Mehraufwand für die Befragten.
Sind meine Testergebnisse signifikant?
Eine Frage, auf die im Rahmen von Kano oft nicht eingegangen wird ist: sind die Ergebnisse meines Tests signifikant? Grund hierfür ist, dass ein solcher Test im ursprünglichen Modell nicht vorgesehen ist. Eine Möglichkeit, zu prüfen, ob die Zuordung eines Features in eine der Kategorien als signifikant angesehen werden kann, liefert der Fong Test².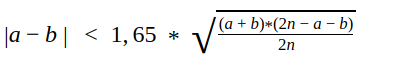
Formel zur Berechnung des Fong-Tests
Während die oben stehende Ungleichung auf den ersten Blick sperrig aussieht, gestaltet sich die Berechnung recht einfach:
- a bezeichnet der Häufigkeit innerhalb der Kategorie mit den meisten Nennungen (also der Kategorie, der das Feature zugeordnet wurde)
- b bezeichnet die Häufigkeit innerhalb der Kategorie mit den zweit-meisten Nennungen
- n ist die Summer der Bewertungen oder Anzahl der Probanden, die in der Auswertung berücksichtigt werden
Der Fong-Test gilt dann als signifikant, wenn die Aussage der Ungleichung nicht wahr ist. Wie aus der Ungleichung hervorgeht hängt das Ergebnis des Fong-Tests vor allem davon ab, wie groß der Unterschied zwischen der Zuordnung zur ersten und der Zuordnung zur zweiten Kategorie ist.


Beispiel Berechnung des Fong-Tests für die Features vier und fünf
Liefert der Fong-Test signifikante Ergebnisse (im Beispiel ist das Ergebnis für Feature vier signifikant, das für Feature fünf jedoch nicht), kann also davon ausgegangen werden, dass das Feature signifikant öfter der entsprechenden Kategorie zugeordnet wurde, als den anderen Kategorien.
Insgesamt helfen die oben erläuterten Kennwerte einerseits, Entscheidungen in Trade-Off Situationen zu erleichtern (Satisfaction/Dissatisfaction Koeffizient, direkte Abfrage der Wichtigkeit) und Muster innerhalb der befragten Zielgruppe aufzudecken (demografische Cluster), andererseits können getroffene Entscheidungen zusätzlich mit etablierten statistischen Kennwerten belegt werden (Fong-Test).
Natürlich kann man Kano Analysen selbst auswerten. Allerdings kann man sich diese Arbeit mit dem Einsatz des richtigen Tools auch sparen. Kano+ hilft nicht nur beim Erstellen von Fragebögen, sondern wertet die Ergebnisse auch automatisch aus!
¹Mkpojiogu, E. & Hashim, N. (2016). Understanding the relationship between Kano model’s customer satisfaction scores and self-stated requirements importance. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4769705/
²Fong, D. (1996). Using the self-stated importance questionnaire to interpret Kano questionnaire results.The Center for Quality Management Journal, 5, 21 – 24.

 in Germany
in Germany
Vielen Dank für die tolle Erläuterungen zur Messung, Auswertung und Prüfung.
Es freut mich sehr, dass dieses tolle Modell beschrieben, dargestellt und diskutiert wird.
Wir bei eresult setzen oft auf KANO. Dabei verwenden wir, u.a. aus Gründe der Forschungseffizient, eine Einfach-Skala. Details dazu findet ihr / finden Sie auf unserer Website:
–// https://www.eresult.de/user-research/anforderungen/anforderungsanalyse-kano .